Docker 的工作原理
Docker 是什么?
Docker 可以打包应用到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,且之间不会有任何接口冲突
它由以下部分组成
- 镜像(Images):Docker 镜像是用于创建 Docker 容器的模板
- 容器(Container):容器是独立运行的一个或者一组应用。镜像相当于类,容器相当于类的实例
- Docker 客户端(Client):Docker 客户端通过命令行或者其他工具使用 Docker API 与 Docker 的守护进程通信
- Docker 主机(Host):一个物理或者虚拟的机器用于执行 Docker 守护进程和容器
- Docker 守护进程:是 Docker 服务端进程,负责支撑 Docker 容器的运行以及镜像的管理
- Docker 仓库:用于保存镜像,类似于代码托管中心,Docker Hub 提供了庞大的镜像集合供使用(类似于 npm)
传统虚拟机和 Docker 的区别
Docker 容器是在操作系统层面上实现虚拟化,直接复用本地主机的操作系统,而传统虚拟机则是在硬件层面实现 虚拟化,与传统的虚拟机相比,Docker 优势体现在启动速度极快、占用体积小
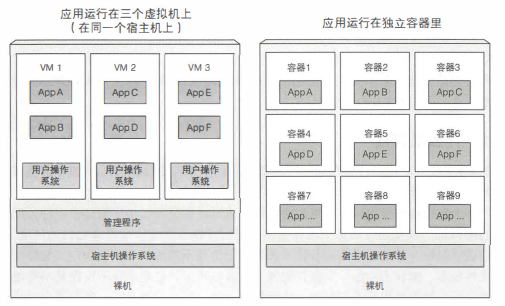
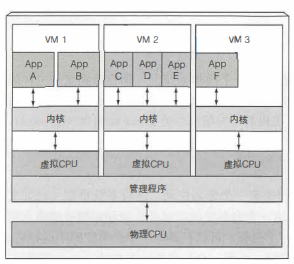
在那些虚拟机之下是宿主机的操作系统与一个管理程序,它将物理硬件资源分成较小部分的 虚拟硬件资源, 从而被每个虚拟机里的操作系统使用。 运行在那些虚拟机里的 应用程序会执行虚拟机操作系统的系统调用, 然后虚拟机内核会通过管理程序在宿主机上的物理来CPU执行x86指令。
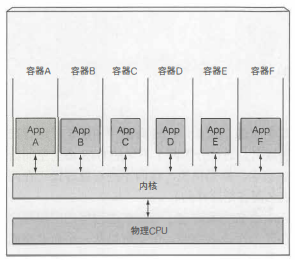
多个容器则会完全执行运行在宿主机上的同一个内核的系统调用, 此内核是唯一一个在宿主机操作系统上执行x86指令的内核。 CPU也不需要做任何对虚拟机能做那样的虚拟化.
Docker 镜像加载原理
docker 的镜像实际上由一层一层的文件系统组成,这种层级的文件系统 UnionFS
Union 文件系统是 Docker 镜像的基础。镜像可以通过分层来进行集成,基于基础镜像(没有父镜像),可以制作各种具体的应用镜像,联合加载会把各层文件系统叠加起来,这样最终的文件系统会包含所有底层文件和目录。
而这些镜像也只需记录容器修改的部分(就像 git 那样)
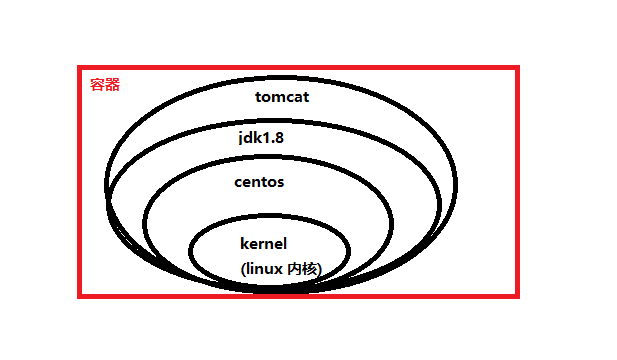
Linux 系统实际上分 bootfs 和 roorfs
- bootfs:主要就是负责引导内核到内存,这个所有发行版的 Linux 都是一样的
- roorfs:就是各种不同的操作系统发行版
所以实际下载的 Ubuntu 镜像就是是这个 roorfs 部分
构建镜像时,Dockerfile 中每一条单独的指令都会创建一个新层。 镜像构建的过程中,拉取基础镜 像所有分层之后,再在新的一层进行下一步操作
UnionFS 系统的好处
采用这种分层结构最大的一个好处就是共享资源,比如有多个镜像都从相同的 base 镜像构建而来,那么宿主机只需要在磁盘上保存一份 base 镜像
同时内存中也只需要加载一份 base 镜像,就可以为所有容器服务了。而且镜像的每一层都可以被共享。
docker 镜像都是只读的,当容器启动时,一个新的可写层被加载到镜像的顶部。这一层通常被称作 “容器层” ,“容器层” 之下的都叫镜像层。这样就只需记录容器修改的部分就行了(就像 git 那样)
所以可以注意到 pull 镜像时也是一层一层的下载的
d1e017099d17: Pull complete
717377b83d5c: Pull complete
...
容器实现隔离机制介绍
如果多个进程运行在同一个操作系统上,那容器到底是怎样隔离它们的。
有两个机制可用:
第一个是 Linux 命名空间, 它使每个进程只看到它自己的系统视图(文件、进程、网络接口、主机名等); 第二个是 Linux 控制组 (cgroups),它限制了进程能使用的资源量(CPU、 内存、 网络带宽等)。
用命名空间隔离进程可见性
默认情况下,每个 Linux 系统最初仅有一个命名空间。所有系统资源(诸如文件系统、 用户 ID、 网络接口等) 属于这一个命名空间。
如下检查进程的命名空间
# $$ 这个程式的PID(脚本运行的当前进程ID号)
$ ls -l /proc/$$/ns
lrwxrwxrwx 1 alsritter alsritter 0 Apr 14 16:25 cgroup -> 'cgroup:[4026531835]'
lrwxrwxrwx 1 alsritter alsritter 0 Apr 14 16:25 ipc -> 'ipc:[4026531839]'
lrwxrwxrwx 1 alsritter alsritter 0 Apr 14 16:25 mnt -> 'mnt:[4026531840]'
lrwxrwxrwx 1 alsritter alsritter 0 Apr 14 16:25 net -> 'net:[4026532008]'
lrwxrwxrwx 1 alsritter alsritter 0 Apr 14 16:25 pid -> 'pid:[4026531836]'
lrwxrwxrwx 1 alsritter alsritter 0 Apr 14 16:25 pid_for_children -> 'pid:[4026531836]'
lrwxrwxrwx 1 alsritter alsritter 0 Apr 14 16:25 time -> 'time:[4026531834]'
lrwxrwxrwx 1 alsritter alsritter 0 Apr 14 16:25 time_for_children -> 'time:[4026531834]'
lrwxrwxrwx 1 alsritter alsritter 0 Apr 14 16:25 user -> 'user:[4026531837]'
lrwxrwxrwx 1 alsritter alsritter 0 Apr 14 16:25 uts -> 'uts:[4026531838]'
具体的命名空间作用参考 Linux 命名空间的笔记
但是你能创建额外的命名空间,以及在它们之间组织资源。 对于一个进程,可以在其中一个命名空间中运行它。进程将只能看到同一个命名空间下的资源。当然,会存在多种类型的多个命名空间,所以一个进程不单单只属于某一个命名空间, 而属于每个类型的一个命名空间。
存在以下类型的命名空间:
- Mount (mnt)
- Process ID (pid)
- Network (net)
- Inter-process communicaion (ipd)
- UTS
- User ID (user)
每种命名空间被用来隔离一组特定的资源。 例如, UTS 命名空间决定了运行在命名空间里的进程能看见哪些主机名和域名。 通过分派两个不同的 UTS 命名空间给一对进程, 能使它们看见不同的本地主机名。 换句话说, 这两个进程就好像正在两个不同的机器上运行一样(至少就主机名而言是这样的)。
同样地, 一个进程属于什么 Network 命名空间决定了运行在进程里的应用程序能看见什么网络接口。 每个网络接口属于一个命名空间, 但是可以从一个命名空间转移到另 一个。 每个容器都使用它自己的网络命名空间, 因此每个容器仅能看见它自己的一组网络接口
用 cgroups 隔离进程资源
另外的隔离性就是限制容器能使用的系统资源。 这通过 cgroups 来实现。 Cgroups 是 control groups 的缩写,是Linux内核提供的一种可以限制,记录,隔离进程组(process groups)所使用物理资源的机制。
$ cat /proc/$$/cgroup
# cgroups 主要由 task,cgroup,subsystem 以及 hierarchy 组成
12:perf_event:/
11:pids:/user.slice/user-1000.slice/session-1.scope
10:rdma:/
9:freezer:/1@dde/uiapps/18
8:devices:/user.slice
7:memory:/1@dde/uiapps/18
6:cpu,cpuacct:/user.slice
5:net_cls,net_prio:/
4:cpuset:/
3:blkio:/1@dde/uiapps/18
2:hugetlb:/
1:name=systemd:/user.slice/user-1000.slice/session-1.scope
0::/user.slice/user-1000.slice/session-1.scope
Linux 系统每个进程都可以自由竞争系统资源,有时候会导致一些次要进程占用了系统某个资源(如CPU)的绝大部分,主要进程就不能很好地执行,从而影响系统效率,重则在 linux 资源耗尽时可能会引起错杀进程。因此 linux 引入了 linux cgroups 来控制进程资源,让进程更可控。
一个进程的资源(CPU、 内存、 网络带宽等)使用量不能超出被分配的量。 这种方式下, 进程不能过分使用为其他进程保留的资源, 这和进程运行在不同的机器上是类似的。
镜像构建原理与上下文
如果注意,会看到 docker build 命令最后有一个 .。这个 . 表示当前目录,这个路径并不止是在指定 Dockerfile 所在路径,而是指上下文路径
首先我们要理解 docker build 的工作原理。Docker 在运行时分为 Docker 引擎(也就是服务端守护进程)和客户端工具。Docker 的引擎提供了一组 REST API,被称为 Docker Remote API。
而如 docker 命令这样的客户端工具,则是通过这组 API 与 Docker 引擎交互,从而完成各种功能。因此,虽然表面上我们好像是在本机执行各种 docker 功能,但实际上,一切都是使用的远程调用形式在服务端(Docker 引擎)完成。也因为这种 C/S 设计,让我们操作远程服务器的 Docker 引擎变得轻而易举。
构建过程不是由 Docker 客户端进行的,而是将整个目录的文件上传到 Docker 守护进程并在那里进行的。
当我们进行镜像构建的时候,并非所有定制都会通过 RUN 指令完成,经常会需要将一些本地文件复制进镜像,比如通过 COPY 指令、ADD 指令等。而 docker build 命令构建镜像,其实并非在本地构建,而是在服务端,也就是 Docker 引擎中构建的。那么在这种客户端/服务端的架构中,如何才能让服务端获得本地文件呢?
这就引入了上下文的概念。当构建的时候,用户会指定构建镜像上下文的路径,docker build 命令得知这个路径后,会将路径下的所有内容打包,然后上传给 Docker 引擎。这样 Docker 引擎收到这个上下文包后,展开就会获得构建镜像所需的一切文件。
如果在 Dockerfile 中这么写:
COPY ./package.json /app/
这并不是要复制执行 docker build 命令所在的目录下的 package.json,也不是复制 Dockerfile 所在目录下的 package.json,而是复制 上下文(context) 目录下的 package.json。
因此,COPY 这类指令中的源文件的路径都是相对路径。这也是为什么 COPY ../package.json /app 或者 COPY /opt/xxxx /app 无法工作的原因,因为这些路径已经超出了上下文的范围,Docker 引擎无法获得这些位置的文件。如果真的需要那些文件,应该将它们复制到上下文目录中去。
将 Dockerfile 放到了硬盘根目录去构建,结果发现 docker build 执行后,在发送一个几十 GB 的东西,极为缓慢而且很容易构建失败。那是因为这种做法是在让 docker build 打包整个硬盘,这显然是使用错误。
一般来说,应该会将 Dockerfile 置于一个空目录下,或者项目根目录下。如果该目录下没有所需文件,那么应该把所需文件复制一份过来。如果目录下有些东西确实不希望构建时传给 Docker 引擎,那么可以用 .gitignore 一样的语法写一个 .dockerignore,该文件是用于剔除不需要作为上下文传递给 Docker 引擎的。
References
- 《Kubernetes in Action》
- 使用 Dockerfile 定制镜像
- Docker 镜像原理
- Docker Hub